**MCP 协议的采样机制全解析**
一、什么是采样(Sampling)机制
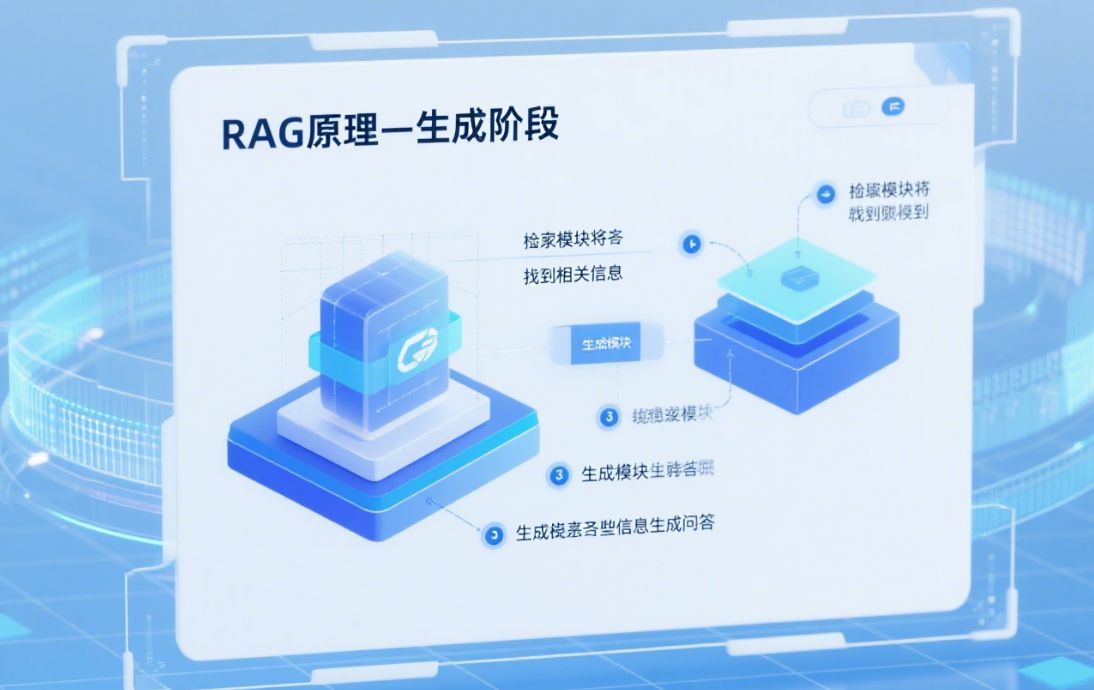
采样是 MCP(Model Context Protocol)中新加入的关键特性,允许 **MCP 服务器向 MCP 客户端发起 LLM 生成请求**。通过这一机制,服务器可在自身逻辑中嵌套调用大语言模型,执行分析、推理或文本生成,而客户端始终掌握模型选择、成本控制与安全审批权。
二、角色与整体流程
1. **服务器 → 客户端**:发送 `sampling/createMessage` 请求,包含消息历史、系统提示、模型偏好等参数。
2. **客户端**:
1. 验证并可视化请求(人类可修改或拒绝)。
2. 选择合适模型并执行生成(temperature、maxTokens 等采样参数可调)。
3. 审核结果后返回给服务器。
3. **服务器**:接收生成内容并继续后续业务逻辑,实现“嵌套智能”。
三、请求消息结构(核心字段)
```json
{
"method": "sampling/createMessage",
"params": {
"messages": [{ "role": "user", "content": { "type": "text", "text": "示例问题" }}],
"systemPrompt": "你是帮助型助手。",
"includeContext": "thisServer",
"modelPreferences": {
"hints": [{ "name": "claude-3-sonnet" }],
"costPriority": 0.3,
"speedPriority": 0.8,
"intelligencePriority": 0.5
},
"temperature": 0.7,
"maxTokens": 200,
"stopSequences": ["\n\n"]
}
}
- messages:会话历史,支持文本 / 图片 / 音频。
- systemPrompt:可选系统级提示,客户端可修改或忽略。
- includeContext:控制是否附带其他服务器上下文(none / thisServer / allServers)。
- modelPreferences:模型选择三优先级 + hints 建议。
- temperature / maxTokens / stopSequences:常见采样参数。
四、模型选择与优先级策略
- costPriority、speedPriority、intelligencePriority 范围 0–1,客户端根据权重在可用模型池中做多目标折中。
- hints 提供模型或家族的名称片段,客户端可做等价映射。
- 客户端最终决定使用何种模型,确保本地资源、成本与隐私要求得到满足。
五、安全与人类监督
- 用户在环(Human-in-the-Loop):客户端应展示请求与生成内容,用户可修改或拒绝。
- 速率与成本控制:客户端可实施限流,避免过度调用。
- 内容校验:对提示与生成结果做长度、敏感词、私密信息过滤。
- 审计日志:记录每次采样请求与响应,便于追溯。
六、典型应用场景
- Agent 工作流嵌套:服务器在执行工具链时实时询问 LLM 进行决策。
- 自动代码修复:服务器处理编译错误后,用采样机制让 LLM 生成补丁候选。
- 智能数据分析:服务器拉取数据库样本后,请求 LLM 生成洞察与可视化说明。
- 对话式 RAG:在返回检索结果前,让 LLM 先对片段进行总结或重写。
七、最佳实践
- 提示精简:仅提供必要信息,减少 token 成本。
- 分步生成:长任务拆分多次采样,控制上下文大小。
- 缓存命中:对重复请求进行结果缓存,降低开销。
- 错误兜底:捕获生成失败,回退到简化提示或替代模型。
- 监控指标:跟踪生成延迟、成本与拒绝率,持续优化业务策略。