什么是向量库?它与大模型的关系详解
一、向量库是什么?
向量库(Vector Database)是一种用于存储和检索高维向量数据的数据库系统。它的核心功能是根据“相似度”进行搜索,而不是传统的关键词匹配。这些向量通常由大语言模型(LLM)或嵌入模型将文本、图像等数据转化而来。
向量是模型将信息编码成的一组高维数字表示。例如,一段文本可能被转换为一个包含 768 个维度的向量。这种表示方式能够捕捉语义特征,使得“意思相近”的内容在向量空间中距离更近。
二、向量库的作用与典型应用场景
- 语义搜索:用户输入问题,系统找到语义最相似的文本片段进行回答。
- 智能问答系统(RAG 架构):与大模型结合,实现基于知识库的准确回答。
- 推荐系统:通过用户行为向量匹配内容向量,提升个性化推荐效果。
- 图像/视频检索:将视觉内容转化为向量,进行相似图片或片段搜索。
主流向量库工具包括 FAISS(Meta)、Milvus(Zilliz)、Pinecone、Qdrant、Weaviate 等。
三、向量库与大模型的关系
向量库与大模型通常配合使用,共同构建一个具备“记忆”能力的智能系统,常见流程如下:
- 大模型将输入数据转化为向量(即 Embedding)
- 向量库存储所有内容的向量化表示
- 用户输入问题 → 模型将问题编码为向量
- 在向量库中检索出相似内容
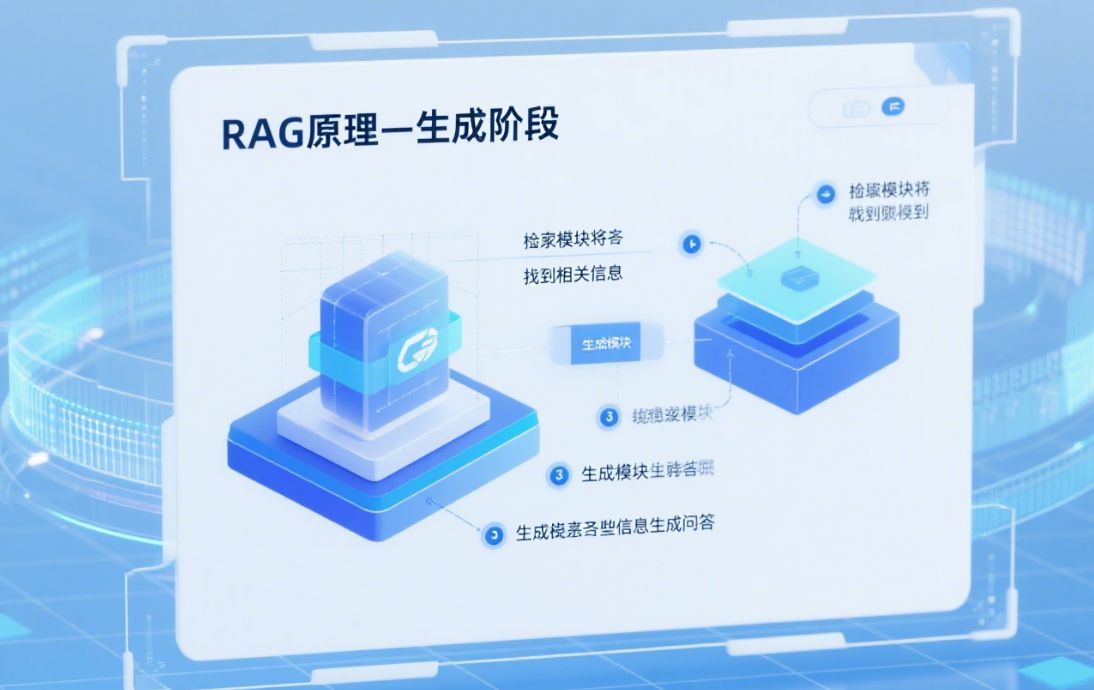
- 模型使用这些检索结果来生成回答
这种架构被称为 RAG(Retrieval-Augmented Generation),是当前企业知识问答系统、智能客服、AI 搜索引擎中的主流方案。
四、向量库 ≠ 模型,但两者互补
- 向量库 = 存储“知识”的外脑
- 模型 = 负责“理解和生成”的大脑
模型没有长期记忆,而向量库提供了低成本、高效可控的“记忆扩展”,两者结合才能实现强大的 AI 能力。
五、一句话总结
向量库是大模型“查找知识”的关键组件,通过相似度搜索,让模型具备了更强的记忆力与上下文感知能力,是构建高质量 AI 系统不可或缺的一部分。